Dado que el tema de Alta disponibilidad me apasiona bastante, y ya que alguno de vosotros me ha realizado alguna pregunta en privado y por correo, a raíz los post que publique en mi blog sobre Always On o incluso la Combinación de Always On con Service Broker + Multitas, artículos que recomiendo su lectura para tener una visión general, ahora voy a comentaros algo mas sobre el mundo de la Alta disponibilidad ligado con SQL Server desde la versión 2008 R2, versión que bajo mi punto de vista, es donde se marca la diferencia respecto a versiones anteriores. Mi intención no es abordar el tema con un gran profundidad técnica, aunque si lo solicitáis me plantearé publicar algo mas técnico… ... Continuar leyendo
Podría hablaros de datos, plataformas, como trabajar con los datos transaccionales o como soportar todos los sistemas de la línea de negocio u organizaciones,… Pero lo que aquí os quiero comentar, es el tema: de ser capaces de poder explotar esa información “cruda” que tenemos en nuestro sistema, el ser capaces de transformar esos datos en información, y aportar valor de negocio, ya que puede suponer una ventaja diferencial, muy importante, y motivo por el que quiero destacaros y hablaros de BI (Business Intelligence)... Continuar leyendo
Big Data, no significa tener una base de datos enorme, tampoco tiene por que ser un Datawarehost enorme,… Independientemente de cuantos datos se tenga, Big Data es una solución para almacenar y procesar datos no estructurados con datos si estructuraos, independientemente que hablemos de escenarios transaccionales, tabulares, multidimensionales… y es independiente de que los datos no estructurados vengan de una red social, de un sensor, de un medidor, ficheros de log, lo que fuere…... Continuar leyendo
La parte de Service Broker, es un desconocido dentro de SQL Server, y sobretodo es la que mas mezcla la parte de desarrollo con la parte de infraestructura.... Continuar leyendo
Nueva solución de alta disponibilidad para SQL Server 2012, de hecho, Always On en realidad no es ninguna tecnología, es un paraguas que cubre un abanico muy amplio de tecnologías, donde quizás la tecnología mas reconocida de ese abanico sea los Grupos de Disponibilidad (Availability Groups). ... Continuar leyendo
Mecanismo de monitorización y control de acceso a los recursos del servidor.... Continuar leyendo
El tema del particionado, ya apareció en SQL Server 2005, y básicamente lo que nos va a permitir, es conseguir coger un único objeto relacional (una tabla), y particionarla en múltiples archivos sobre el sistema de discos. Es de cajón, que esto nos va a dar una serie de escenarios muy interesantes, que todos nos podemos imaginar o de hecho que todos probablemente conozcamos. Como es la posibilidad de mantener un único objeto con una gran cantidad de datos históricos y de evitar el tener que hacer tareas de mantenimiento que por naturaleza no tengan mucho sentido sobre estos datos históricos, como por ejemplo la fragmentación de índices, ya que no va ha ser un problema sobre los datos históricos, pero la fragmentación si hay que tenerla en cuenta para los datos mas transaccionales o actuales. Esto es en grandes rasgos lo que se dá en los casos básicos de particionado.... Continuar leyendo
Quiero compartir con vosotros las razones para elegir, desde ya mismo, encaminar nuestros proyectos a Windows Server 2012, SQL Server 2012… son las siguientes:... Continuar leyendo
Contamos con modificaciones y nuevas opciones de licenciamiento en SQL Server 2012, respecto a versiones anteriores. Como novedad, ahora podremos disfrutar de licencias para una sola Máquina Virtual (VM), de esta forma con las bases de datos que no necesitan todo el potencial del servidor físico, podemos ahorrar al adquirir este tipo de licencias. Con un ejemplo, suponiendo que una maquina virtual tiene asignada 4 cores, necesitará licenciar 4 cores, independientemente del número de porcesadores y cores por procesador que disponga el servidor.... Continuar leyendo
CLR (Common Language Runtime) permite sacar gran partido de .NET desde el interior de SQL Server. Funcionalmente hablando, podríamos hablar de Visual Basic como predecesor (aunque muy de lejos) de CLR, ya que Visual Basic convierte su lenguaje en llamadas a API de Windows de bajo nivel… ... Continuar leyendo
SQL SERVER usa dos tipos de memoria; una llamada BUFFER POOL – que está restringida por el parámetro de max server memory, y otra como proceso como tal que no está restringida y que puede llegar a ocupar dependiendo de las diferentes cargas de proceso entre 1 a 2 gb.
En SQL Server se pueden diferenciar dos grandes secciones de memoria:
-Memoria para paginas (Datos)
-Memoria del proceso de SQL
Sobre la memoria de proceso de SQL no tenemos control ninguno y SQL va a consumir la que crea necesaria (Normalmente en torno a 200M-300M) dependerá de servidores enlazados, proveedores de acceso, etc... y que puede llegar a ocupar dependiendo de las diferentes cargas de proceso entre 1 a 2 gb
Sobre la memoria de páginas tenemos más flexibilidad, podemos controlar su tamaño máximo “max server memory” tamaño minimo “min server memory” e incluso podemos habilitar una opción “lock pages in memory” que hace que las páginas de datos no puedan ser eliminadas por otros procesos del sistema.
En este artículo tenemos información sobre “max server memory” y “min server memory”:... Continuar leyendo
Cross-site scripting (XSS) en el Administrador de informes SQL Server en Microsoft SQL Server 2000 Reporting Services SP2 y SP4 de SQL Server 2005, 2008 SP2 y SP3, 2008 R2 SP1, y 2012, permite a atacantes remotos inyectar secuencias de comandos web o HTML a través un parámetro no se especifica, también conocido como "Vulnerabilidad XSS reflejado".... Continuar leyendo
Un equipo puede tener una o varias instancias de SQL Server instaladas. Y hasta ahora cada instancia de SQL Server contenia las bases de datos del sistema (master, msdb, tempdb) y una o varias bases de datos de usuaro. Con la nueva versión Denali (SQL Server 2012) se incorporan un nuevo tipo de base de datos, estas se denominan: bases de datos autocontenidas, las cuales lo que pretenden es eliminar las dependencias entre la base de datos y la instancia.... Continuar leyendo
Descripción del funcionamiento de la carga masiva
Son varios los factores que afectan al rendimiento de las operaciones de carga masiva (por ejemplo, la instrucción BULK INSERT y la utilidad bcp). En las siguientes secciones se describen estos factores y se sugieren formas de mejorar el rendimiento. Los parámetros descritos se aplican a la instrucción BULK INSERT. Existen también parámetros similares para otros métodos de carga masiva.... Continuar leyendo
Actualizar tablas muy grandes puede llevar mucho tiempo y a veces puede tardar horas en terminar, producirse problemas de bloqueo. En ocasiones queremos modificar cientos de registros de una misma tabla y necesitamos que el proceso sea lo mas ligero posible…... Continuar leyendo
En ocasiones nos pueden pedir optimizar las consultas y puede ocurrir que se necesite reescribir la consulta real, ya que la pérdida de rendimiento normalmente puede ser causada por tener subconsultas anidadas. ... Continuar leyendo
Lo normal es que a uno no le pregunten sobre este tipo de cosas y que tenga que lidiar con lo que hay para ir, poco a poco, ajustándolo a lo que las buenas prácticas aconsejan. ... Continuar leyendo
Hay ocasiones puntuales en el que el rendimiento de una consulta puede resultar peor en una versión más reciente de SQL Server, aunque no es lo normal. Hay que tener presente que los motores tratan las consultas de forma diferente. No hay un patrón ni un ajuste que puedas aplicar para que todo funcione mejor, más allá de seguir las buenas prácticas, toca revisar cada sentencia que haya perdido rendimiento y mejorarla, en ocasiones indexando, en otras reescribiendo la consuta por otra mejorada...... Continuar leyendo
La existencia de bloqueos es algo normal y necesaria en las bases de datos relacionales, esto garantiza la integridad de los datos, no permitiendo actualizaciones concurrentes sobre los mismos datos o la lectura de datos que están siendo actualizados en ese momento por otras transacciones...... Continuar leyendo
A diferencia de que solo puede existir una clave principal en cada tabla, si usas dicha clave difiniendo un campo único, si lo que deseas es forzar la unicidad en otras columnas, puedes hacerlo creando índices unicos para esos campos, ya que podemos crear varios incides unicos en una misma tabla y podras incluir valores NULL, si lo deseas, aunque solo un NULL se permitirá por columna.... Continuar leyendo
Si una operación permanece abierta en la base de datos, ya sea intencionalmente o no, esta operación puede bloquear otros procesos.... Continuar leyendo
Una cosa es el proceso de instalación del clúster de Windows (en el que se basa el clúster de SQL) y otra la propia instalación de una instancia de SQL Server clusterizada. También es diferente el tema de qué cuenta realiza este proceso de instalación y qué cuenta inicia el servicio de SQL Server.... Continuar leyendo
La configuración del nivel RAID de los discos es sólo uno de los muchos parámetros a considerar cuando se está diseñando la parte de Entrada/Salida para SQL Server. En http://sqlcat.com/whitepapers/archive/2007/11/21/predeployment-i-o-best-practices.aspx tienes una lista de los documentos y artículos que son de recomendada lectura para este tema tan importante. A modo rapido lo mejor es RAID 10, o si no, RAID 5 para los archivos de datos (el cual penaliza las escrituras, pero una base de datos es principalmente lecturas) y RAID 1 para los logs. Pero esto es un resumen muy básico, y dependiendo de la configuración puede que te rinda peor una configuración que otra, por eso la recomendación de lectura de esos documentos Hay mucha diferencia en implementar dichos Raid por software o por hardware... Y aunque la base es para todos igual, hay diferencias de rendimiento si tus discos son internos controlados por una controladora SCSI, o son externos (cabinas EVA, Symetix...) a los cuales se accede por tarjetas HBA + fibra... Para todos los casos una correcta alineación de los discos, la recomendada por el fabricante, que en muchos casos se pasa por alto, mejora el rendimiento de forma notable. Sobre este último punto os paso un artículo mío: http://microsoftsqlsecret.fullblog.com.ar/alineamiento-de-particiones-en-discos-para-bases-de-datos-sql-server.html Sobre performance y RAID: En http://msdn.microsoft.com/es-es/library/ms178048.aspx donde veras: 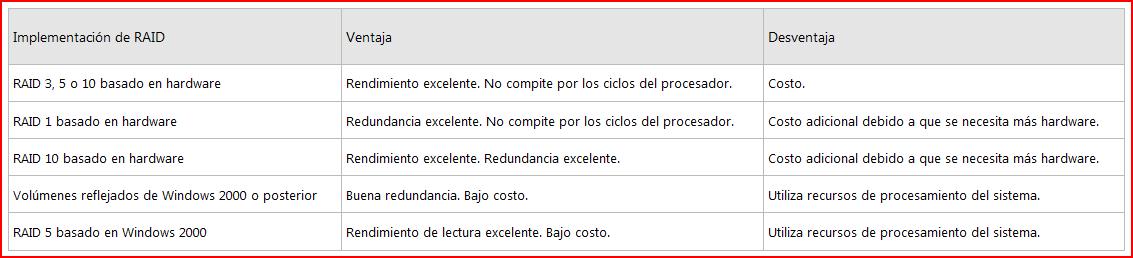 Os dejo un enlace donde pondeis ver como funcionan algunos Niveles RAID: http://msdn.microsoft.com/es-es/library/ms190764.aspx donde destaco:   Fuentes:... Continuar leyendo
El otro día me llamaron, porque desde hacía algunas semanas, venían observando que había aumentado de forma considerable el tiempo de construcción de los Cubos OLAP y así mismo el crecimiento de una de las base de datos del sistema: la tempdb.
Los tiempos de creación superaban las 8 o incluso 10 horas…... Continuar leyendo
TDE puede tener un efecto mínimo o notable en el momento de ejecutar una carga de trabajo sobre la base de datos, los aumentos en la utilización de la CPU producidos por el cifrado de los datos, pueden ser diferentes según los entornos donde se trabaje, y las características de las tablas existentes en la base de datos. La encriptación TDE es transparente para las aplicaciones (no necesitan ser modificadas, todo el proceso lo asume la base de datos), lo cual mejora o facilita su uso en aplicaciones de terceros o que no puedan ser modificadas. Si vas ha encriptar una bd existente, te recomendo la creación de una nueva base de datos vacía donde, una vez configurado el método de encriptación a utilizar, vuelques toda la información de nuestra base de datos actual. De esta forma evitas dejar páginas con datos desencriptados (en el caso de encriptación no TDE), restos en el log de transacciones... Todos los esfuerzos a nivel de base de datos se pueden volatilizar tan pronto como salen los paquetes por la red. Las aplicaciones que hagan uso de los datos privados deben ser auditadas para asegurar que no dejan rastros en forma de ficheros temporales, caché, etc en los puestos clientes o servidores web, donde se perdería la encriptación de la base de datos Descripción del Cifrado de datos transparente (TDE), recomendada la lectura: http://msdn.microsoft.com/es-es/library/bb934049.aspxExixten multitud de test donde analizan el impacto, como por ejemplo este: http://www.databasejournal.com/features/mssql/article.php/3815501/Performance-Testing-SQL-2008146s-Transparent-Data-Encryption.htmDe destacar son las palabras textuales del articulo " Cifrando datos con SQL Server 2005" de Maximiliano D. Accotto: "No recomiendo cifrar todo sino solamente lo necesario, ya que las operaciones de cifrado/descifrado perjudican el rendimiento global, con lo cual se debería poner a un lado de la balanza la seguridad, y la performance al otro."Un detalle que no suele decirse es que el TDE anula la compresion de bk. Entonces si tu tarea de bk estaba generando archivos de 4G y eras feliz porque en 2005 eran de 40G, olvidate porque volveras a los 40. Asi mismo los tiempos de bk aumentan considerablemente. Ha raiz de este hilo, hay quien me ha preguntado sobre la encriptacion de TDE, si era completa para toda la bd, si se hacia en una base de datos existente... Pues bien, en el documento ( http://msdn.microsoft.com/es-es/library/bb934049.aspx) puedes leer: “Puede encontrar el estado del cifrado de la base de datos utilizando la vista de administración dinámica sys.dm_database_encryption_keys. Para obtener más información, vea la sección "Vistas de catálogo y vistas de administración dinámica"anteriormente en este tema.En TDE, se cifran todos los archivos y grupos de archivos de la base de datos. Si algún grupo de archivos de una base de datos está marcado como READ ONLY, se producirá un error en la operación de cifrado de la base de datos.Si una base de datos se utiliza en una creación de reflejo de la base de datos o en un trasvase de registros, se cifrarán ambas bases de datos. Las transacciones del registro se cifrarán cuando se envíen entre ellas. ImportanteLos índices de texto completo nuevos se cifrarán cuando una base de datos esté configurada para cifrarse. Los índices de texto completo creados previamente se importarán durante la actualización y usarán TDE una vez que los datos se hayan cargado en SQL Server. La habilitación de un índice de texto completo en una columna puede ocasionar que los datos de dicha columna se escriban en texto simple en el disco durante el examen para la indización de texto completo. No se recomienda crear un índice de texto completo para datos confidenciales cifrados.”Luego yo diría que la respuesta es que quitando esta pequeña salvedad, todos los archivos quedan cifrados. Respecto a T-Logs: “Al habilitar una base de datos para utilizar TDE, se "pone a cero" la parte restante del registro de transacciones virtual para exigir el registro de transacciones virtual siguiente. Esto garantiza que no quede ningún texto sin cifrar en los registros de transacciones una vez configurada la base de datos para el cifrado. Puede encontrar el estado del cifrado del archivo de registro en la columna encryption_state de la vista sys.dm_database_encryption_keys, como en este ejemplo:”USE AdventureWorks2008R2; GO /* The value 3 represents an encrypted state on the database and transaction logs. */ SELECT * FROM sys.dm_database_encryption_keys WHERE encryption_state = 3; GO Son también relevantes los siguientes puntos: “El cifrado de datos transparente y la base de datos del sistema tempdbLa base de datos del sistema tempdb se cifrará si alguna otra base de datos de la instancia de SQL Server se cifra mediante TDE. Esto podría tener un efecto en el rendimiento de las bases de datos no cifradas de la misma instancia de SQL Server. Para obtener más información sobre la base de datos del sistema tempdb, vea Base de datos tempdb.Cifrado de datos transparente y replicaciónLa replicación no replica automáticamente los datos de una base de datos habilitada para TDE en un formato cifrado. Debe habilitar por separado TDE si desea proteger las bases de datos de suscriptor y de distribución. La replicación de instantáneas, así como la distribución inicial de datos para la replicación transaccional y de mezcla, puede almacenar los datos en archivos intermedios sin cifrar; por ejemplo, los archivos bcp. Durante la replicación transaccional o de mezcla, el cifrado puede habilitarse para proteger el canal de comunicaciones. Para obtener más información, vea Cómo habilitar conexiones cifradas en el motor de base de datos (Administrador de configuración de SQL Server).”Yo creo que el documento está bastante claro… Aqui os dejo un blog, donde se cuenta todo el proceso de cifrado: http://blogs.solidq.com/elrincondeldba/post.aspx?id=18&title=encriptaci%C3%B3n+segura+en+sql+server+2008+con+tdeFuentes: ... Continuar leyendo
Voy a comentar de forma detallada la manera de crear bases de datos y que parámetros hay que reconfigurar, para un entorno Sharepoint 2007 - SQL Server 2005 o 2008
Parametros:... Continuar leyendo
ASP.NET tiene un proveedor de membresia (Membership) para tareas de login, permisos por roles/grupo de usuarios sean mas faciles de implementar. Viene configurado para utilizar una base de datos SQL Server, registra tablas y procedimientos por nosotros, y luego es transparente (con alguna configuracion previa)... Continuar leyendo
La diferencia entre Remote Server y linked server. Según los libros en pantalla: "Remote servers are supported in SQL Server for backward compatibility only. New applications should use linked servers instead. For more information, see" Para un remote server dice: " remote server configuration allows for a client connected to one instance of SQL Server to execute a stored procedure on another instance of SQL Server without establishing a separate connection. Instead, the server to which the client is connected accepts the client request and sends the request to the remote server on behalf of the client." y para linked server: "A linked server configuration enables SQL Server to execute commands against OLE DB data sources on remote servers" En resumen linked server sustituyen a remote servers con un modelo mejor de seguridad Si hacemos esta consulta, sobre nuestra instancia: SELECT srvname,isremote FROM master..sysservers El campo isremote, te devolvera: 0 o 1, para cada uno de tus servidores vinculados. 1 -> sera como remoto. 0 -> sera vinculado. Las propiedades-configuración visualmente (por venta), pueden ser identicas, pero como he dicho, el vinculado contempla un modelo mejor de serguridad frente al remoto. Creo que remote server, solo se puede crear por script, y no por ventanas desde el Management Studio como el linked server. Apunte y recopilación por Norman M. Pardell... Continuar leyendo
LINQ to SQL es un componente de .NET Framework (3.5 o suprior). Cuando la aplicación se ejecuta, LINQ to SQL convierte a SQL las consultas integradas en el lenguaje del modelo de objetos y las envía a la base de datos para su ejecución. Cuando la base de datos devuelve los resultados, LINQ to SQL los vuelve a convertir en objetos con los que pueda trabajar en su propio lenguaje de programación. es de asegurarse de que las consultas de LINQ a SQL cierran correctamente los recuros (entre los que se encuentran las conexiones a base de datos) y no tratan de volver a utilizar el DataContext. Aunque Teoricamente LINQ limpia-cierra correctamente los recursos, hay casos en los que puede quedar abierta la conexión, en función del uso de su código, como por ejemplo con una mala reutilización del DataContext. Dejo este enlace: http://msdn.microsoft.com/en-us/library/bb386929.aspx Al igual que ASP.net, donde SqlConnection. NET está diseñado para ser un objeto de muy corta duración, debería abrirse justo antes de que lo necesite y asegurarnos de que se cierra poco después de que lo utilice, no es recomendable que se trate de almacenar en caché un objeto SqlConnection. Para LINQ es similar el no tratar de almacenar en caché DataContext, basta con crear un nuevo DataContext con la misma cadena de conexión. Cuando se utiliza LINQ contra SQL es frecuente la apertura y el cierre del DataContext, y hay que intentar no volver a utilizar el DataContext en el código, sólo se tiene que volver a crear cada vez que se consulta a la base de datos. Apunte y recopilación por Norman M. Pardell... Continuar leyendo
Las operaciones ORDER-BY, GROUP-BY y DISTINCT son
todas tipos de ordenación. El procesador de consultas de SQL Server implementa
la ordenación de dos modos distintos. Si los registros ya están ordenados por
un índice, el procesador sólo tiene que usar el índice. De lo contrario, el
procesador debe utilizar una tabla de trabajo temporal para ordenar primero los
registros. Esta ordenación preliminar puede provocar retrasos iniciales
considerables en dispositivos con una CPU lenta y memoria limitada, y debería
evitarse si el tiempo de respuesta es importante.
En el contexto de índice con varias columnas, para que ORDER-BY o GROUP-BY
tengan en cuenta un índice concreto, las columnas ORDER-BY o GROUP-BY
deben coincidir con el conjunto de prefijos de columnas de índice en el orden
exacto. Por ejemplo, el índice CREATE INDEX Emp_Name ON Employees ("Last
Name" ASC, "First Name" ASC) puede ayudar a optimizar las
siguientes consultas:... Continuar leyendo
Los índices pueden utilizarse para acelerar la evaluación de ciertos tipos
de cláusulas de filtro. Si bien todas las cláusulas de filtro reducen el
conjunto de resultados final de una consulta, algunas de ellas también ayudan a
reducir la cantidad de datos que se deben explorar.
Un argumento de búsqueda (SARG) limita una búsqueda porque especifica la
coincidencia exacta, un intervalo de valores o una conjunción de dos o más
elementos combinados con AND. Presenta uno de los siguientes formatos:... Continuar leyendo
Es recomendable que siempre cree índices en las claves principales. También
suele ser muy útil crear índices en claves externas, puesto que tanto las
claves principales como las externas se utilizan con frecuencia para combinar
tablas. Los índices de estas claves permiten al optimizador calcular los
algoritmos de combinación de índices más eficaces. Si la consulta combina
tablas utilizando otras columnas, a menudo es útil crear índices en esas
columnas por la misma razón.
Cuando se crean las restricciones de claves principales y externas, SQL
Server crea automáticamente índices para
ellas y las utiliza para optimizar las consultas. Recuerde que es aconsejable
crear claves principales y externas lo más pequeñas posible, ya que las
combinaciones son más rápidas.... Continuar leyendo
Una tabla pequeña es aquella cuyo contenido cabe en una o pocas páginas de
datos. Evite indizar tablas muy pequeñas porque normalmente es más eficaz
realizar una exploración de tablas. De este modo, se evita tener que cargar y
procesar las páginas de índices. Si no crea un índice en las tablas muy
pequeñas, está eliminando la posibilidad de que el optimizador seleccione una.
... Continuar leyendo
Los índices de varias columnas son extensiones naturales de los índices de
una sola columna. Los índices de varias columnas son útiles para evaluar
expresiones de filtro que coinciden con un conjunto de prefijos de columnas de
clave. Por ejemplo, el índice compuesto CREATE INDEX Idx_Emp_Name ON Employees
("Last Name" ASC, "First Name" ASC) ayuda a evaluar las
siguientes consultas:
·
... WHERE "Last Name" = 'Doe'... Continuar leyendo
Los índices en las columnas utilizadas en la cláusula WHERE de las
consultas importantes normalmente mejoran el rendimiento. Sin embargo, esto
depende del grado de selectividad del índice. La selectividad es la proporción
de filas resultantes respecto al total de filas. Si la proporción es baja,
significa que el índice es muy selectivo, ya que puede deshacerse de la mayoría
de las filas y reducir en gran medida el tamaño del conjunto de resultados. Por
consiguiente, se trata de un índice muy útil. En cambio, un índice que no es
selectivo no es tan útil.
Los índices únicos son los más selectivos. Sólo puede coincidir una fila,
lo que es realmente útil para las consultas que pretenden exactamente devolver
una fila. Por ejemplo, un índice en una sola columna de Id. servirá de ayuda
para encontrar con rapidez una fila concreta.... Continuar leyendo
La creación de índices útiles es uno de los métodos más importantes para lograr
un mejor rendimiento de las consultas. Los índices útiles ayudan a encontrar
los datos con menos operaciones de E/S de disco y un menor uso de los recursos
del sistema.
Para crear índices útiles, debe comprender cómo se utilizan los datos, los
tipos y las frecuencias de ejecución de las consultas y cómo el procesador de
consultas puede utilizar los índices para encontrar los datos con rapidez.... Continuar leyendo
Uno de los primeros
elementos que debe aparecer en cualquier lista de comprobación para la
optimización del rendimiento de SQL Server es el ajuste de los índices de una
base de datos. La capacidad del optimizador de consultas de SQL Server para
hacer un buen uso de los índices durante la ejecución de una consulta depende
no sólo de la creación de índices eficaces sino también del estado de estos.
Una serie de vistas y funciones de administración dinámicas (DMV y DMF,
respectivamente), incluidas por primera vez en SQL Server™ 2005, puede ayudar a
los administradores de bases de datos a determinar la eficacia de los índices y
a descubrir cualquier problema de rendimiento.
... Continuar leyendo
Existen
distintas formas de ejecutar un Paquete DTSX de SSIS , cada una de las cuales
puede presentar ciertas ventajas o inconvenientes según en el caso particular
en que la deseemos aplicar.
- Ejecutar un Paquete DTSX desde
Business Intelligence Development Studio (BIDS). Desde BIDS podemos crear
nuestros Proyectos de SSIS , que estarán formados por nuestros Paquetes
DTSX. Estos Paquetes DTSX se almacenarán en el File System, y NO se
almacenarán ni en SQL Server (MSDB) ni en el Package Store. Como mucho,
podremos integrar BIDS con Visual Source Safe, o en todo caso, desplegar o
publicar los Paquetes DTSX del Proyecto en un Package Store, en un
servidor SQL Server, o en otro File System. La principal ventaja de BIDS,
es que al tratarse de la herramienta de desarrollo de SSIS ,
podemos ver de forma gráfica la ejecución del Paquete DTSX, incrustar
Lectores de Datos para ver los datos que se mueven por nuestros Flujos de
Datos (Data Flows), etc. Es muy cómodo, pero sólo se trata de una
herramienta de desarrollo y se limita a la ejecución de Paquetes DTSX
almacenados en el File System.
... Continuar leyendo
FORCESEEK
obliga al optimizador de consultas a usar sólo una operación de Index Seek como
ruta de acceso a los datos de la tabla o vista a la que se hace referencia en
la consulta.
Comentaros que
el operador Index Seek utiliza la capacidad de
búsqueda de los índices para recuperar filas de un índice… Al forzar una
operación de index seek, se puede lograr un mejor rendimiento de las consultas.... Continuar leyendo
Lo que vamos a realizar es mover las bases de datos de una instancia a otra ubicación diferente.
Sacamos las rutas de todas las bases de datos, con la consulta en la bd master:... Continuar leyendo
Como ya he contado en otros artículos,
( ver
aquí ), los desencadenadores
DDL se pueden ejecutar cada vez
que cree, eliminar , modificar… un
objeto de base de datos. Estos desencadenador o triggers
DDL se les pueden especificar las
opciones de disparo (es decir, el
tipo de operaciones para las que queremos que se activen).
También he contado
en anterior artículo con un ejemplo como se especifica la
ejecución de los disparadores cuando
se crea una tabla nueva, ( ver
aquí ). Sin embargo,
de añadir es que en lugar de especificar un disparador
para cada operación, podemos crear un trigger DDL que se dispare con un grupo de operaciones, en ese caso, el disparador se ejecutará con cada una de las operaciones
de ese grupo de eventos. Por ejemplo, si ha
especificado DDL_DATABASE_LEVEL_EVENTS en lugar de CREATE_TABLE, se registrará
cada eventos de CREATE_TABLE, ALTER_TALBE y DROP_TABLE,
tras su ejecución.... Continuar leyendo
La auditoría de una instancia de SQL Server o de una
base de datos de SQL Server implica el seguimiento y registro de los eventos
que se producen en el sistema. En SQL Server puedes utilizar varios métodos de
auditoría, como se describe en Auditoría (motor de
base de datos) -> http://msdn.microsoft.com/es-es/library/cc280526.aspx.
A partir de SQL Server 2008 Enterprise, también puedes configurar la auditoría
automática mediante SQL Server Audit.
Paso a comentar un par de formas fáciles y personalizadas, para que podáis
crear vuestras propias auditorias. Ayudarte de procedimientos almacenados que
te permitan capturar información adicional del usuario que realiza el cambio, si
se puedes (que en ocasiones no se puede), encapsular las modificaciones en
procedimientos almacenados y en esos mismos procedimientos incluir el registro
en tablas de auditoría. Esta solución mediante procedimientos almacenados es
buena pues te da mucha flexibilidad en cuanto a grabar datos de la aplicación
que no están accesibles mediantes triggers.
De cualquier forma...la auditoría con triggers tiene una ventaja respecto a
hacerlo mediante un stored procedure y es que a través de triggers quedan
auditados todos los cambios de datos, no solo los que se hacen a través de tu
aplicación sino también los que se hacen por fuera (por ejemplo cambios hechos
con el managment studio a través de un update/delete/insert).
Programar triggers de auditoría..no es nada sencillo, más bien es una tarea tediosa.
Ya desde SQL Server 2005 tenemos los DDL Triggers. Son triggers que se
ejecutan cuando se produce la ejecución de instrucciones DDL (create, alter,
drop, ...). Hasta este momento esto no era posible, sólo podíamos crear
triggers para instrucciones DML (insert, update, delete). Con esta nueva funcionalidad
ya podemos, por ejemplo auditar las creaciones, modificaciones y borrados de
objetos en nuestra base de datos, e incluso, no permitir que se realicen estas
acciones.
La sintaxis de DDL triggers, es:... Continuar leyendo
|
 |
|
.Sobre mí |
Norman M. Pardell
MCITP: Database Administrator & Database Developer, SQL Server 2008. MCC Award Certificate. Consultor Senior de bases de datos en Capgemini España, S.L. Asesoramiento en implementación, desarrollo y gestión de bases de datos en grandes compañías. Actualmente, asignado a proyecto en compañía líder en el sector energético global. Más de 10 años trabajando con SQL Server (y otros gestores de BBDD)
»
Ver perfil
|
|
|
 ...
...