
A la hora de diseñar consultas, para extraer datos de SQL Server, podemos optar por varias vías:
- Una de ellas es crear una solución iterativa, desempeñándola con la aplicación (bien sea con un programa T-SQL) de tipo cursor, como por ejemplo, para obtener todas las sumas de las ventas que ha realizado un determinado empleado, entre dos fechas… aunque sea una consulta simple, se pude complicar, si a ello le sumamos obtener información de todos los empleados, el % de las ventas frente a todos los compañeros, etc… Para lo que abriríamos un cursor y empezaríamos a iterar. Este tipo de soluciones, conllevan una pérdida de rendimiento brutal, y no aconsejo que os pongáis a diseñar una solución con cursores. Es una forma sencilla y rápida de destrozar el potencial de un servidor SQL Server. Olvidémonos de usar cursores, ya que tenemos que pensar en conjuntos. Cuando nos paremos a pensar en una solución a nuestras consultas, no hay que dejar de pensar que SQL Server es un motor de base de datos relacional que trabaja con conjuntos de datos, que son los que queremos explotar haciendo consultas T-SQL, y una forma mala de hacerlo es utilizando cursores.
- Otra opción es usar consultas agrupadas, si optamos por agrupar, cuando hablo de agrupación estoy pensando en una suma, en una media, en mínimos…en operaciones que son de tipo agrupado. Se tendrán que hacer en determinados momentos cuando tengamos que dar una solución, el inconveniente de estas operaciones es la imposibilidad de mezclar los cálculos del agrupado y el nivel de detalle, hasta ahora era casi imposible que a la hora de obtener una suma, obtener también el nivel de detalle de donde viene esa suma…
-Otra forma que podemos adoptar es hacer subconsultas, el problema de estas son la complejidad, si no se hacen bien, añaden complejidad al calculo que se quiere llegar a realizar… Las subconsultas, bien sean, con WITH (consultas CTE), o con la utilización de subquerys, que nos ofrecen la oportunidad de sacar datos agrupados con el detalle de la información del agrupamiento, tenemos que intentar evitarlas… Las subconsultas que se hacen dentro de los campos a mostrar en el Select son muy ineficientes y las subconsultas que se hacen detrás del from suelen ser complejas y difíciles de entender
-Otra opción, es hacer Joins… si hacemos un join, dado un determinado problema, puede llegar el caso que podamos consultar o cruzar una tabla consigo misma. Este tipo de escenarios, como por ejemplo para obtener descendientes de…, o agrupados hasta un determinado momento de una fecha sobre la información que se tiene en una tabla… Todo este tipo de información que se puede obtener a partir de SELF JOIN, generalmente son consultas de complejidad cuadrática.
Tenemos que llegar a la conclusión que tenemos que pensar en conjuntos, cuando trabajemos con SQL Server, tenemos que generar una solución desarrollada en conjuntos, bien sea mediante consultas agrupadas, mediante Joins, o mediante subconsultas… que al final sean consultas donde no aparece el efecto cursor.
No olvidemos que como conjunto, entendemos una reunión de objetos “sin ningún” orden y con una propiedad común. (SQL Server tiene la cláusula ORDER BY por que no te garantiza el orden en los conjuntos…)
Para dar solución a lo anterior, a consultas con agregados y detalles de los mismos, aparece en SQL Server 2012 la cláusula OVER, que optimiza las soluciones anteriores… Con la clausula OVER el motor optimiza el tiempo de ejecución y los bloqueos de las filas, ya que el motor trabaja sobre los datos ya obtenidos, en vez de volver a recuperarlos de origen.
Como ejemplo, os mostrare la clausula OVER con las funciones:
RANK() Si se especifica una expresión numérica, la función Rank determina el rango basado en uno de la tupla especificada mediante la evaluación de la expresión numérica especificada con la tupla. Si se especifica una expresión numérica, la función Rank asigna el mismo rango a las tuplas con valores duplicados del conjunto.
DENSE_RANK () Devuelve el rango de filas dentro de la partición de un conjunto de resultados, sin ningún espacio en la clasificación. El rango de una fila es uno más el número de rangos distintos anteriores a la fila en cuestión.
NTILE () Distribuye las filas de una partición ordenada en un número especificado de grupos. Los grupos se numeran a partir del uno. Para cada fila, NTILE devuelve el número del grupo al que pertenece la fila.
CREATE TABLE Personas (ID INT IDENTITY, PRIMERNOMBRE VARCHAR(50) NOT NULL, SEGUNDONOMBRE VARCHAR(50) NOT NULL)
GO
DELETE FROM dbo.Personas
GO
INSERT INTO dbo.Personas VALUES('JUAN','AVILA')
INSERT INTO dbo.Personas VALUES('ALDO','LADERAS')
INSERT INTO dbo.Personas VALUES('ALDO','LADERAS')
INSERT INTO dbo.Personas VALUES('ALDO','LADERAS')
INSERT INTO dbo.Personas VALUES('JUAN','VICTORIO')
INSERT INTO dbo.Personas VALUES('VICTOR','MORENO')
INSERT INTO dbo.Personas VALUES('ADRIAN','LUNA')
INSERT INTO dbo.Personas VALUES('ADRIAN','LUNA')
INSERT INTO dbo.Personas VALUES('ADRIAN','AQUINO')
INSERT INTO dbo.Personas VALUES('JUAN','SAAVEDRA')
INSERT INTO dbo.Personas VALUES('JUAN','SAAVEDRA')
INSERT INTO dbo.Personas VALUES('JUAN','SAAVEDRA')
INSERT INTO dbo.Personas VALUES('JUAN','SAAVEDRA')
INSERT INTO dbo.Personas VALUES('LUIS','SATTUI')
INSERT INTO dbo.Personas VALUES('DANIEL','VILLARAN')
INSERT INTO dbo.Personas VALUES('VICTOR','HUAMAN')
INSERT INTO dbo.Personas VALUES('VICTOR','HUAMAN')
INSERT INTO dbo.Personas VALUES('MIGUEL','HUAMAN')
INSERT INTO dbo.Personas VALUES('LUIS','SANCHEZ')
-- Ejemplo sin partición:
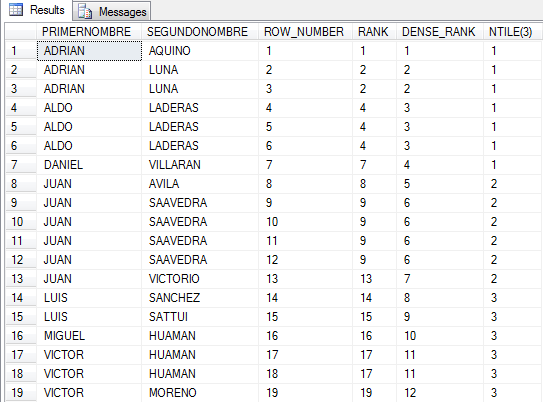
SELECT PRIMERNOMBRE,SEGUNDONOMBRE,
ROW_NUMBER() OVER(ORDER BY PRIMERNOMBRE,SEGUNDONOMBRE) AS ROW_NUMBER,
RANK() OVER(ORDER BY PRIMERNOMBRE,SEGUNDONOMBRE) AS RANK,
DENSE_RANK() OVER(ORDER BY PRIMERNOMBRE,SEGUNDONOMBRE) AS DENSE_RANK,
NTILE(3) OVER(ORDER BY PRIMERNOMBRE,SEGUNDONOMBRE) AS 'NTILE(3)'
FROM dbo.Personas ORDER BY PRIMERNOMBRE
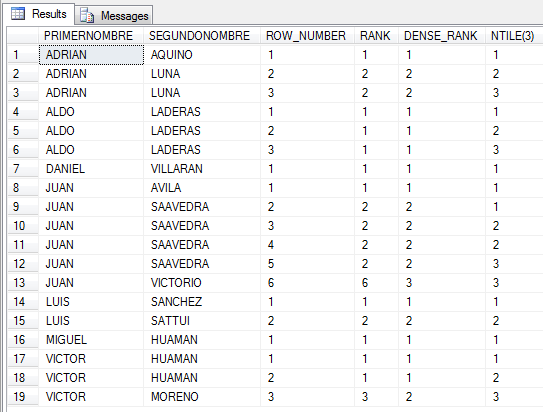
-- Ejemplo con partición
SELECT PRIMERNOMBRE,SEGUNDONOMBRE,
ROW_NUMBER() OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE)
AS ROW_NUMBER,
RANK() OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE) AS RANK,
DENSE_RANK() OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE)
AS DENSE_RANK,
NTILE(3) OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE) AS 'NTILE(3)'
FROM dbo.Personas ORDER BY PRIMERNOMBRE
Para sacar solo los JUAN y quitar los repetidos:
SELECT PRIMERNOMBRE,SEGUNDONOMBRE,
ROW_NUMBER() OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE)
AS ROW_NUMBER,
RANK() OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE) AS RANK,
DENSE_RANK() OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE)
AS DENSE_RANK,
NTILE(3) OVER(PARTITION BY PRIMERNOMBRE ORDER BY SEGUNDONOMBRE) AS 'NTILE(3)'
FROM dbo.Personas where PRIMERNOMBRE = 'JUAN'
Group by PRIMERNOMBRE, SEGUNDONOMBRE ORDER BY PRIMERNOMBRE
Apunte y recopilación por Norman M. Pardell
Puedes consultarme, si deseas cualquier aclaración, pregunta o sugerencia en: Contacto, contestaré tan pronto como me sea posible.