El Query Optimizer es el responsable de obtener el plan de ejecución, de las consultas realizadas en nuestras bases de datos.
Debido a la complejidad de SQL; todas las opciones existentes en un base de datos, tablas, índices, join… hay muchas formas de ejecutar una consulta. El trabajo del Optimizador es encontrar la mejor forma de resolver las consultas. Depende del Query Optimizer, el que una consulta tarde, por ejemplo, minutos o incluso horas frente a milisegundos en resolver la misma consulta. Del buen trabajo que realice el Optimizador depende en gran medida tener un buen Performance en nuestras consultas y aplicaciones.
Es importante conocer la forma en que trabaja el Optimizador, para poder detectar problemas, en muchas ocasiones el Optimizador nos dirá cuales son los problemas para que nosotros los podamos resolver, y en otras ocasiones nosotros podemos ayudar al Optimizador a mejorar los planes de ejecución.
Parameter Sniffing
En esta sección, vamos a intentar optimizar la ejecución de los procedimientos almacenados mediante la creación de planes de ejecución compilados. Se va a tratar las condiciones que se indican en el Where de las consultas con @variables en lugar de valores fijos. Ya que si no usamos @variables, siempre se creará el plan de ejecución para esos valores fijos.
Por ejemplo, dada la variable: @pid, en la siguiente consulta del procedimiento:
CREATE PROCEDURE test (@pid int)
As
SELECT * FROM Sales..SalesOrderDetail
Where ProductID = @pid
El Optimizador pude usar o partir de estas variables/parámetros (@pid), para intentar hacer el mejor plan de ejecución, para resolver una consulta. El Optimizador se basa en las estadísticas para intentar dar ese mejor plan de ejecución.
Voy a tratar de comentar, con mediante un ejemplo, de una forma sencilla, como realiza este trabajo el Optimizador. Ya que cuando aumenta el numero de variables y/o parámetros, se complica la forma en como trabaja.
Por ejemplo, si ejecutamos:
EXEC test @pid = 898
Gracias a las estadísticas, podremos conocer cuales es el Estimated Number or Rowns (Numero de registros estimados). El Optimizador saca este valor de las estadísticas que esta acumulando o ha acumulado…
Para conocer este valor, podemos ejecutar la consulta, (Donde “IX_SalesOrderDetail_ProductID“es el índice creado para la columna ProductID en la tabla SalesOrderDetail):
DBCC SHOW_STATISTICS (‘Sales.. SalesOrderDetail’, IX_SalesOrderDetail_ProductID)
Podemos ver el Estimated Number or Rowns, en el histograma que devuelve la consulta, y ver que es “9”:
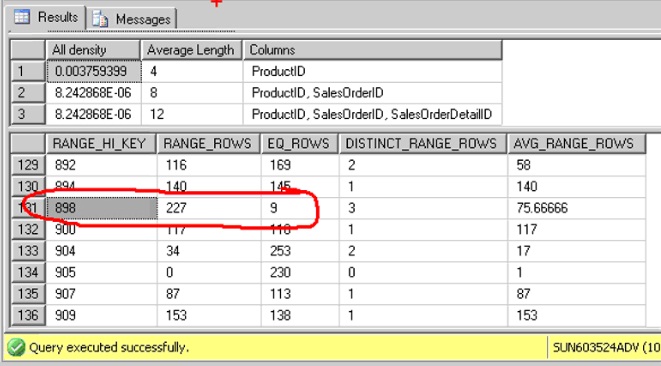
Dependiendo del valor Estimated Number or Rowns (EQ_ROWS), para nuestro caso “9”, el Optimizador va ha tomar decisiones. Si el Optimizador obtiene un numero bajo de registros puede optar por usar un índice para realizar el plan de ejecución, mientras que si se obtiene un número elevado el Optimizador puede optar por realizar un full Scan, table Scan, Index Scan… Es importante que estos números estén actualizados (actualización de estadísticas).
Se aconseja leer: Actualización de estadísticas síncronas o asíncronas mejoran la respuesta del optimizador de consultas. SQL Server
Hay que nombrar, que el Optimizador rehúsa los planes de ejecución ya creados con anterioridad. ¿Por qué se rehúsan los planes de ejecución? Porque optimizar una consulta consume muchos recursos de procesador y nos puede ser muy caro estar optimizando por cada ejecución. Básicamente lo que SQL Server hace, cuando el Optimizador crea un plan, es llevarlo a memoria, y SQL Server va a tratar de rehusar ese plan el mayor número de veces posibles. En ocasiones no es lo adecuado, ni la mejor opción, el rehusar ese mismo plan de ejecución.
Una de las cosas que podemos hacer, para determinar si el plan de ejecución usado por una consulta es el adecuado, Antes de la ejecución de la consulta ejecutamos:
SET STATISTICS IO ON
Y una vez ejecutada la consulta, gracias ha SET STATISTICS IO ON, nos devolverá una pestaña (Messages) donde encontraremos el valor de logical reads -> Paginas leídas. Logical reads, ha de ser inferior al numero de registros devueltos por la consulta (un sitio donde indica el numero de registros devuelto por la consulta, es en la esquina inferior derecha del Management Studio)
Podemos estar sufriendo, que las mismas consultas, según los parámetros de las variables (para nuestro ejemplo @pid), en ocasiones tarden segundos y en otras ocasiones tarden minutos o incluso horas… ya que el plan de ejecución que esta en memoria para esa consulta, no es el adecuado para distintos valores/parámetros de las variables.
Si pensamos que el plan de ejecución, que se esta rehusando (ya creado con anterioridad), no es el adecuado. Podemos borrar los planes de ejecución llevados a memoria, para evitar que los use, luego ejecutaremos nuevamente la consulta para que cree su nuevo plan de ejecución, consultando las estadísticas, con su valor actual.
Para borrar los planes de ejecución llevados a memoria ejecutaremos:
DBCC FREEPROCCACHE
Lo anterior es una práctica que no debe hacerse en servidores de producción, si no en entornos de desarrollo cuando estamos intentando optimizar una consulta.
Para adaptar las consultas, a unos correctos planes de ejecución, pues podemos tener tiempos muy diferentes de ejecución, ya que los parámetros de las variables cambian…, hay diferentes técnicas. Voy a comentar algunas de ellas:
Una de las opciones es usar OPTIMIZE FOR, disponible en versiones de SQL Server 2005 en adelante.
Si hemos detectado que las mayorías de nuestras consultas se benefician de la ejecución de un plan de ejecución, podemos decir al Optimizador de Consultas, que use ese plan de ejecución (por ejemplo para el valor “898”), podremos decir que la primera vez que ejecute este procedimiento lo haga para el valor 898 sea cual sea su valor. Ya que el objetivo es rehusar planes de ejecución, elevamos a memoria el plan de ejecución que deseamos, (ante posibles reinicios de instancias o cualquier acción que elimine los planes de ejecución elevados a memoria), con la primera ejecución:
ALTER PROCEDURE test (@pid int)
As
SELECT * FROM Sales..SalesOrderDetail
Where ProductID = @pid
OPTION (OPTIMIZE FOR (@pid = 898))
Si por el contrario, para la consulta, no tenemos un valor que predomine, como el caso anterior, sino que tenemos un numero X de valores (para nuestro ejemplo @pid) que se ejecutan con las misma frecuencia. No podemos escoger un plan… por lo que podremos decantarnos por: OPTION (RECOMPILE), opción que fuerza a que se recompile y se cree el plan para cada ejecución. No nos beneficiaremos de rehusar los planes ya creados en memoria, y esto conlleva algo de penalización en los tiempos de ejecución, a tener en cuenta cuando una consulta se ejecuta cientos de veces…. El procedimiento quedaría de la forma:
ALTER PROCEDURE test (@pid int)
As
SELECT * FROM Sales..SalesOrderDetail
Where ProductID = @pid
OPTION (RECOMPILE)
Tendremos que hacer un balance de cual es la mejor opción para nuestra aplicación.
Otra de las opciones, mencionar que no es muy recomendada, a no ser que estemos seguro que nos beneficia, es evitar que, al crear el plan de ejecución, el Optimizador use el histograma de las estadísticas, entonces usara valores generales de las estadísticas, estos valores se llaman Densidad. Cada ejecución no importa el valor que tome las variables (para nuestro ejemplo @pid), por que siempre creará el mismo plan de ejecución para todos valores en la misma consulta. De esta forma ahorraremos tiempo de ejecución. Esto se puede hacer por medio de variables locales o usando OPTIMIZE FOR UNKNOWN
Variables locales:
ALTER PROCEDURE test (@pid int)
As
Declare @p int = @pid
SELECT * FROM Sales..SalesOrderDetail
Where ProductID = @p
OPTIMIZE FOR UNKNOWN (solo disponible en versiones SQL 2008 y superiores):
ALTER PROCEDURE test (@pid int)
As
SELECT * FROM Sales..SalesOrderDetail
Where ProductID = @pid
OPTION (OPTIMIZE FOR UNKNOWN)
Os dejo el enlace, para aquellos a quienes les interese es tema, donde se habla de:
Fuentes:
Microsoft, MSDN, Benjamin Nevares
Apunte y recopilación por Norman M. Pardell
Puedes consultarme, si deseas cualquier aclaración, pregunta o sugerencia en: Contacto, contestaré tan pronto como me sea posible.
